

Following a recent and successful attempt at using OpenAI fine-tuning API to generate synthetic data, we wondered how far we could get with a smaller open-weights model such as Mistral 7B Instruct.
The task of fine-tuning a model, is more complex than using OpenAI API, but still relatively simple, thanks to Mistral’s open-source fine-tuning code.
Overall, the results we obtained were a bit less convincing but still impressive given the relative size of the model (7B parameters vs 175B).
Quick reminder of the goal
As described in our previous post, we want to generate synthetic time-series of hourly electricity consumption. Generating such synthetic data with a fine-tuned GPT-3.5 gave excellent results:
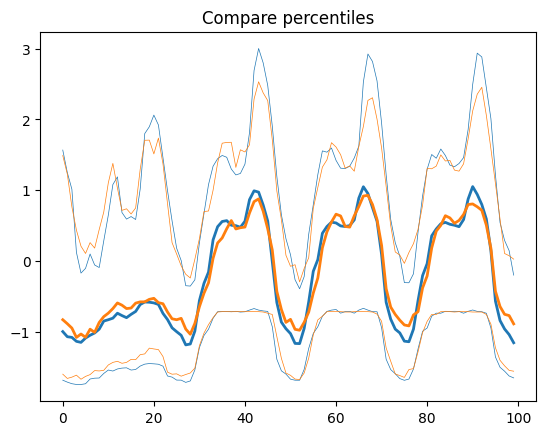
We want to realize the same task with Mistral-7B.
Setup of the experiment
The data is organized in JSON messages in the same way they were for the previous experiment:
{
"messages": [
{"role": "system", "content": "Given a meter ID, you return a series of hourly consumptions given as a json string."},
{"role": "user", "content": "{\"item_id\": \"MT_001\"}"},
{"role": "assistant", "content": "{\"consumption\": [-0.194, -0.089, -0.194, -0.089, -0.141, -0.141, -0.089, -0.194, -0.456, -0.036, 1.751, 0.7, 0.122, -0.562, 0.7, 1.068, -0.509, 1.015, 1.699, -0.194, 0.437, 2.172, 1.12, 0.7, -0.246, -0.194, -0.246, -0.194, -0.246, -0.299, -0.351, -0.351, 1.383, 1.909, 1.856, 2.434, 2.382, 1.699, 2.645, 1.856, 2.855, 0.647, 1.12, -0.246, 0.858, 0.963, 0.279, 0.91, -0.194, -0.246, -0.194, -0.246, -0.351, -0.299, -0.299, 0.174, 1.856, 1.804, 1.699, 2.014, 2.014, 0.7, 1.015, 2.014, 2.96, -0.036, 2.224, 0.332, 0.858, 2.066, 0.858, 1.331, -0.089, -0.036, -0.141, -0.089, -0.141, -0.194, -0.194, 0.174, 1.751, 2.224, 2.54, 2.172, 1.856, 2.277, 0.437, 0.332, 1.751, 3.328, 2.277, 0.174, 0.069, 2.277, 0.647, 0.91, 0.91, 0.91, 0.752, 2.066]}"}
]
}To run the fine-tuning task, we provisioned a virtual machine on AWS with 4 A10 GPUs (g5.12xlarge instance). Then followed the instruction from mistral-finetune with the following parameters:
batch_size: 1
ckpt_freq: 180
data:
data: ''
eval_instruct_data: mistral_finetuning_test.jsonl
instruct_data: mistral_finetuning_train.jsonl
eval_freq: 9
log_freq: 1
lora:
rank: 64
max_steps: 180
model_id_or_path: mistral_models/7B_instruct
no_eval: false
optim:
lr: 6.0e-05
pct_start: 0.05
weight_decay: 0.1
run_dir: mistral_run-2024-06
save_adapters: false
seed: 0
seq_len: 2048
wandb:
key: xxxxxx
offline: false
project: arena-tests
run_name: run-2024-06Finally, we generated new time-series with mistral-inference and generated 200 new series. Descriptive statistics (percentiles, cross-correlation, etc.) show the following:


The distribution of values is strongly shifted toward lower values, but the cross correlation seems to be relatively faithful.
Conclusion
Fine-tuning based synthetic data seem to show acceptable statistical properties even when using a relatively small model.
Of course, although quick tests show none of the original data can be found in the generated dataset, there is no privacy garantee with this approach. For very sensitive data you should rely on formal guarantees of privacy such as Differential Privacy for your synthetic data. Sarus Technologies provides a service for LLM fine-tuning with differential privacy.
If you want to play with this experiment, you can find the code there.
This post is one in a series of posts on AI and privacy. How to use AI and in particular commercial LLMs (for in-context learning, RAG or fine-tuning) with some privacy guarantees but also how AI and LLMs can help us solve privacy challenges. If you are interested in knowing more about existing AI with privacy solutions contact us and try our open-source framework: Arena (WIP).
See also:
- Easy PII replacement for OpenAI, Mistral and Anthropic APIs
- David vs. Goliath in AI
- Quickly Generate Time-Series Synthetic Data with OpenAI’s Fine-Tuning API
.png)


